You may have faced this issue in Evaluation versions or Preview releases or OS you are not activated, it's very easy to remove this. using a free tool you can...
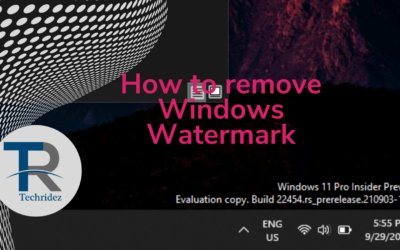
How to remove Windows Watermark
read more

You may have faced this issue in Evaluation versions or Preview releases or OS you are not activated, it's very easy to remove this. using a free tool you can...

Today we will cover how to disable weak cbc ciphers in ssh server, after this you will pass cbc ciphers vulnerability.Environment Red Hat Enterprise Linux 8.x...

NIMIQ Will cryptocurrency replace traditional money? The question is not if but when. So what does it takes to empower real mass adoption? Bitcoin set...
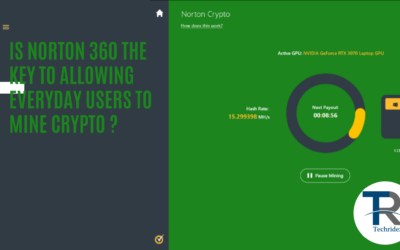
By 2030, studies show that blockchain technology is expected to lift the global GDP up by two trillion US dollars. As more countries are setting trends in...

Chia is a cryptocurrency using a block chain technology.and it uses what is called a proof of space and work consensus mechanism. In short to farm anything...

FreeBSD is an operating system used to power modern servers, desktops, and embedded platforms. A large community has continually developed it for more than...

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur arcu erat, accumsan id imperdiet et, porttitor at sem.
